

A 60-year-old patient walks into a new medical facility. He carries with him a big pile of printed papers of health records containing his reports from all his previous medical providers. The operator at the facility starts entering patient data by physically inspecting the last few entries from his records.
A borrower submits a home loan application. The mortgage provider asks to submit financial documents, and property details. The documents are scanned and sent to the offshore facility for manual data entry. The offshore operator starts a long and painful process of inspecting and entering financial data from the document into spreadsheets. The structured data is returned to the provider the next day and then the further process continues. A similar manual process is used for contract review, legal case precedence, resume processing, invoices consolidations, expense reconciliation, etc.
Every day millions of documents with unstructured are generated, inspected, interpreted, exchanged, and used for decision making. These documents are human-readable but not machine-readable. In the process, sometimes, errors are made, and the core information is lost. Also, such data is open to interpretation from a person looking at it causing inconsistencies further in the chain. It is not easy to exchange such data between multiple parties. Lack of standards to exchange such data in different systems further exasperates the issue. Due to these issues, most of the unstructured data in businesses is left untouched leaving a huge gap in analytics and decision making.
The Platform
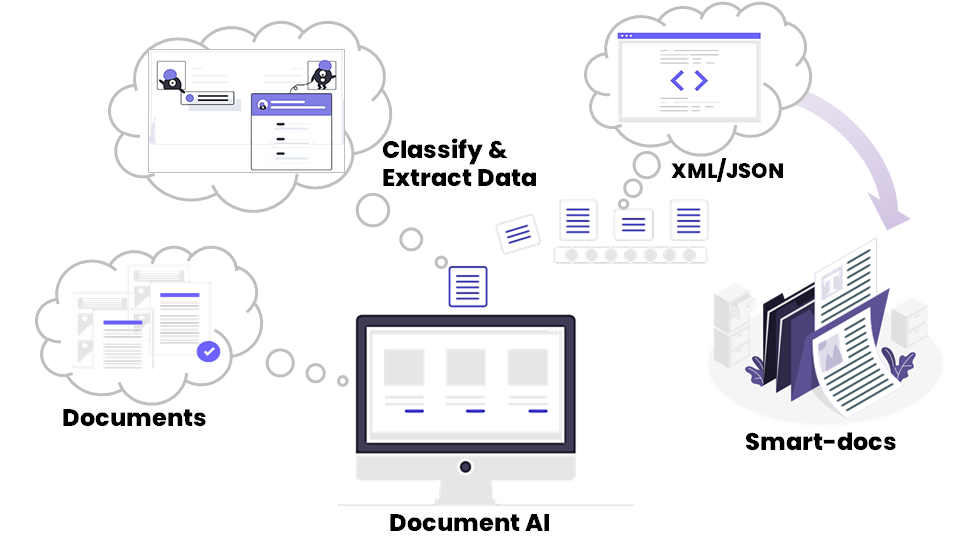
The solution is to classify documents and extract metadata from such unstructured documents using an Intelligent AI-powered document understanding platform. Such a platform can ingest documents in a variety of formats, at scale, and convert them into SMART Docs. SMART docs consist of relevant structured data (XML, JSON) extracted from such unstructured documents.
To convert unstructured documents to SMART docs, different types of extractors are used that can accurately detect and extract information from MS DOC files, Digital PDF files, Scanned PDF files, Images, etc. The unstructured documents may contain a variety of content like title, header/footer, tables, checkboxes, images, signatures, stamps, barcodes, etc. An intelligent document understanding platform performs layout detection to identify each of these areas in the document, OCRs the text or extracts the text based on the document type and creates a structured text output that can be further interpreted. A machine learning-based interpreter can be used to accurately detect and extract values from such a text and generate a corresponding SMART document.
The accuracy of detection can be further enhanced by the use of structured data to give meaning to the unstructured data. A domain-specific dictionary, taxonomy, ontology can be used to support the extraction making it much more efficient and accurate. Such structured data is either fed with the document or extracted from one part of the document and used to interpret other parts or can be retrieved from external sources during document extraction. For example, claims data along with the Electronic Health Record (EHR), use borrower names from one part of the document to search in other parts.
Type of data
A variety of metadata can be extracted from unstructured documents and they can be converted to SMART Docs. It can include but not limited to –
- Labels and associated values with context
- Checkbox values
- Tables with variable columns and rows
- Signature areas
- Handwriting including signatures, dates, stamps
- Named Entities
- Pictures and metadata in pictures – Furniture in property pictures, Anomalies in X-ray or pathology pictures, etc.
Improving the accuracy
The accuracy of extracted data is very important in the financial, medical, and legal domains. In other words, false positives and false negatives have a business cost. To ensure accuracy, manual intervention is needed to quickly inspect and correct any discrepancies between the document and the extracted data. An intelligent document understanding platform provides an intuitive, domain-specific, and fast operations user interface to provide 100% accuracy to the output data. Such a platform also has a built-in, continuous feedback loop to improve automated extraction accuracy based on the manual corrections.
Standards to exchange SMART Docs
The structured data can be exchanged with other systems seamlessly when it follows popular industry standards. For healthcare, FHIR (Fast Healthcare Interoperability Resources) Specification provides an interoperability standard in the US. The Mortgage Industry Standards Maintenance Organization (MISMO) provides a SMART doc standard for exchanging mortgage documents between different systems in the US. The document understanding platform generates structured data such that it can easily be transformed into the industry-standard format.
Enhanced Services
The unlocking of hidden metadata from the vast unstructured documents in an enterprise opens doors to a host of new services that would not have been possible otherwise.
Some of these services include:
- Cross-comparison of data between various documents and other data sources
- Regulatory Audit
- Standards Compliance
- Fraud Detection
- Risk calculations for individuals and property
- Aggregation analytics of quality scores, risks across populations
- Predictive analytics for budgeting, diseases
The document understanding brings in a host of services that not only benefits the businesses but also borrowers, patients, educators, and lawyers. The 60-year old patient can walk into the hospital with no papers since his legacy data is transformed using the document understanding platform into digital SMART EHR and is already sent to the hospital. The borrower receives the loan approval instantaneously since all his papers have been fed and converted to SMART Doc and have been automatically vetted using an intelligent Decision Management System. These benefits directly translate to cost and time savings for the entire ecosystem.

























